고정 헤더 영역
상세 컨텐츠
본문
DeepMind에서 오늘 알람이 떠서 알게된 따끈따끈한 논문입니다.
한달 전인 2월 24일에 아카이브에 올라왔더군요.
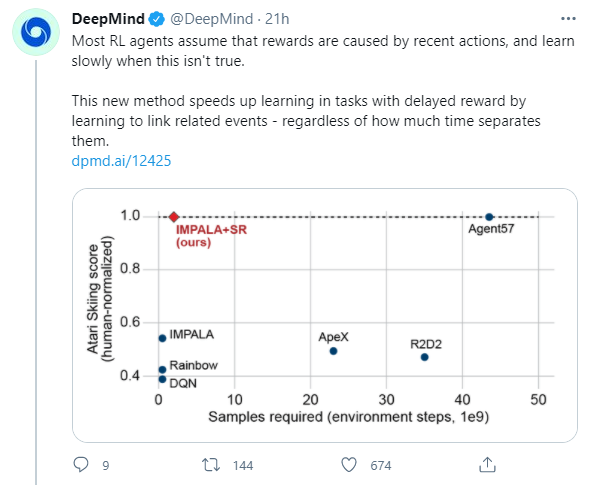
논문링크: arxiv.org/abs/2102.12425
본 논문은 강화학습의 원초적 이슈인 Long-term credit assignment 문제를 해결하는 방법을 다룹니다.
*Long-term credit assignment:
Delayed reward 환경에서 발생하는 문제를 말합니다. 에이전트가 어떠한 적절한 행동을 취하여 desirable한 상태를 얻었음에도, 그에 대한 보상이 한참 후에 주어진다면 적절한 행동을 강화하는 데 장애가 됩니다. 설령 그 적절한 행동이 작업을 성공하는 정말 결정적인 행동이었다 하더라도, 해당 행동에 높은 기여도를 부여(credit assignment)하기에는 그 행동 이후부터 실제로 보상을 얻기까지의 무관한 행동들도 보상에 기여한 것처럼 고려되기 때문입니다.
서론
본 논문은 Delayed reward 환경에서 기존의 TD-learning만으로는 reward를 전파시키는 과정에서 정말로 중요한 원인이 되는 상태의 reward에 대한 기여도가 희석되어 올바른 학습이 어렵다는 한계를 꼬집으면서 시작합니다.
결국 어떠한 원인이 되는 상태와 그에 따른 결과인 보상을 얻는 상태 간의 인과관계(Causality) 파악이 필요하다는 것입니다.
그러면서, delayed reward의 원인이 되는 상태와 실제로 dealyed reward가 주어지는 나중의 상태를 서로 연관짓는 SA 학습 (State-associative learning)을 해결 방법으로 제안합니다.
SA 학습을 하면 delayed reward의 원인이 되는 상태에서 더 가지 않아도 바로 그 보상에 대한 수치를 알아낼 수 있습니다.
이렇게 알아낸 보상을 Synthetic returns라고 정의합니다.
그리고 이 Synthetic returns를 원래의 보상과 적절히 배합한 형태의 보상을 학습에 이용하면 기존의 TD-learning으로 잘 된다는 것입니다.
간단히 말해, Delayed reward가 TD-learning의 문제를 야기한다면, 아예 Non-delayed reward로 변환해서 TD-learning하자는 겁니다.
(물론 여기서 TD-learning이 non-delayed reward 환경에서는 잘 작동한다는 전제가 깔립니다.)
방법

제안하는 SA 학습의 도식입니다.
논문에서 모델을 설명하는 그림은 이게 전부입니다.
(좌측)
에이전트는 매 타임스텝마다 환경 상태를 관측하고(Observation) 인코딩한 상태 표상(State representation)을 만듭니다.
이때 LSTM을 사용하여, 상태 표상은 이전 상태 표상과 현재 관측값이 합쳐진 꼴입니다.
그리고 그 상태 표상들을 메모리에 쌓습니다.
(중앙)
이 부분이 SA learning의 핵심입니다.
c, g, b가 제일 먼저 눈에 들어옵니다.
이들은 모두 신경망으로, 실제로는 학습할 녀석들입니다.
하지만 설명의 편의를 위해 모두 완벽하게 학습되어 있다고 가정하고, 각각의 역할을 알아보겠습니다.
State-associative는 어떤 보상의 원인이 되는 상태와 그 보상이 실제로 주어지는 상태를 서로 연관짓는다고 했습니다.
즉 한 에피소드 내에서, 시간상으로 멀리 떨어진 두 상태를 연결짓겠다는 것입니다.
이때 그 연관성의 정도를 나타내주는 함수가 g이고,
그 보상의 정도를 나타내주는 함수가 바로 c입니다.
현재 상태가 s_t라고 할때, Memory에는 0부터 t-1까지의 과거 상태들이 쌓여 있습니다.
그림을 보시면, 각각의 과거 상태들에 대해 c가 출력한 값을 모두 더한 값에 g가 곱해집니다.
이때 g는 Sigmoid gate로, [0, 1] 범위의 출력을 가집니다.
g가 0이면 과거 상태들이 현재 상태와 보상적으로 전혀 연관이 없고, 1이면 완벽하게 연관이 있다는 것이죠.
만약 g가 1이면, 과거의 모든 상태들에 따라 c가 제출한 값을 모두 더한 것이 현재의 상태와 연관된 delayed reward의 정도가 됩니다.
반면 g가 0이면, c와 상관없이 현재 상태와 연관된 delayed reward가 없다고 해석할 수 있습니다.
주의할 점은, 여기서 말하는 연관이라는 뉘앙스를 잘 이해하셔야 합니다.
만약 에이전트가 열쇠를 먹은 뒤로 한참 후에 문을 땄을 때 보상이 발생했다고 한다면,
연관되는 두 상태는 '열쇠를 먹는 순간'과 '문을 딴 순간'입니다.
'열쇠를 먹는 순간'과 '문을 딴 직후'는 연관성이 없습니다.
즉, g가 1인 때는 현재 상태가 '문을 딴 순간'일 때뿐입니다.
다시 그림을 보면, 방금까지 c와 g로 계산한 값에 b를 더해주고 있습니다.
b는 현재 상태가 현재 보상에 미치는 정도입니다.
결국 c와 g로 계산한 delayed reward 관련 값과, 현재 보상 관련 값인 b를 더해서 출력한 reward를 현재 reward의 추정값으로 사용하고 c, g, b를 학습하는 것입니다.
c, g, b 학습의 손실식은 다음과 같습니다.
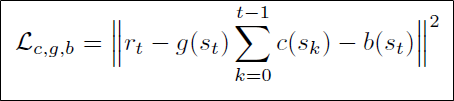
c, g, b를 통한 reward 추정값과 실제 reward 간의 차이를 손실로 정의하여 reward prediction을 정의했습니다.
(우측)
위의 reward prediction의 목적은 학습된 c를 얻어내는 것입니다.
이 c가 바로 Synthetic return입니다.
이걸 가지고 원래 보상과 합쳐 다음의 새로운 보상을 만듭니다.

하이퍼파라미터인 알파와 베타를 조정해서, 시간을 넘어 associate된 보상 c(s_t)와 실제 현재에 주어지는 보상 r_t를 적당히 배합하여 조합하는 것을 알 수 있습니다.
에이전트는 이렇게 만든 새로운 보상으로 TD 학습을 적용하여 강화학습하게 됩니다.
실험
실험은 Chain, Catch, Key-to-Door, Atari Pong, Atari Skiing의 5가지 환경에서 진행되었습니다.
여기서는 중요 내용을 담고 있는 Catch와 Key-to-Door만 소개하겠습니다.

위는 바구니를 움직여서 떨어지는 공을 받아내는 Catch 환경에서 Synthetic return (SR)을 사용해서 실험한 결과입니다.
기존 알고리즘으로는 딥마인드의 기존 분산 강화학습 알고리즘인 IMPALA를 사용했습니다.
a) Catch는 공을 받는 즉시 보상이 주어지기 때문에, delayed reward 환경이 아닙니다.
따라서 IMPALA를 쓰든 IMPALA+SR을 쓰든 기존 환경(Standard)에서는 다 잘 해냅니다.
b) 그런데 이제 환경을 조금 바꿔서, 에피소드가 다 끝난 뒤에야 보상이 한꺼번에 들어오도록 설정합니다.
이 환경(With delayed rewards)에서는 IMPALA+SR만이 제대로 수행해내는 것을 볼 수 있습니다.
c) 왜 그런가 보기 위해 IMPALA+SR의 완전히 delayed된 환경에서 스텝 경과에 따른 SR 수치를 찍어봅니다.
초반, 중반, 후반의 에피소드를 골라 (각각 episode return이 7, 15, 20일 때) 확인해본 결과, 공을 받아낸 순간순간마다 SR이 spike가 튀는 것을 볼 수 있습니다.
이 실험 결과는 SR이 delayed reward에 온전하게 대응하고 있음을 보여줍니다.
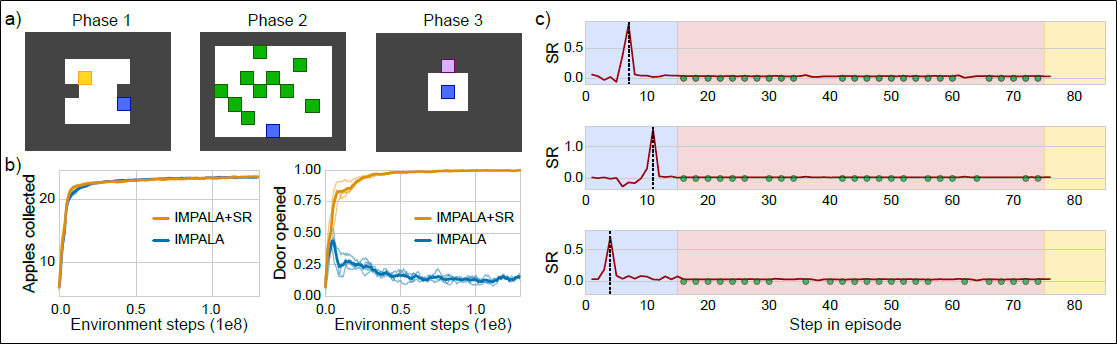
결과는 Key-to-Door 환경에서도 일관적입니다.
b)를 보시면 사과를 먹는 행위에 대해서는 IMPALA도 잘 합니다.
그러나 키를 먹고 문을 따는 행위는 IMPALA+SR만이 온전하게 수행할 수 있었습니다.
c)는 IMPALA+SR에서 3개의 에피소드를 꼽아 스텝 경과에 따른 SR 수치입니다.
빨간색 원들은 각각 사과를 먹었을 때이고, spike가 튄 부분은 키를 먹었을 때입니다.
사과를 먹는 행위는 즉각 보상이므로 SR에는 반응이 없습니다.
하지만 키를 먹는 상태는 delayed reward의 원인이 되는 상태이므로 SR에서 spike가 튑니다.
이 실험 결과는 SR이 즉각 보상엔 반응하지 않으면서, delayed reward의 원인이 되는 상태에서만 잘 반응하고 있음을 보입니다.
실제 학습에 이용하는 보상은 (SR + 원래보상)이기 때문에, 즉각적 보상과 delayed reward가 둘 다 반영되게 되어 에이전트는 효과적으로 TD-learning을 할 수 있게 됩니다.
결론
사실 결론은 아니고, 논의 쪽에 가깝습니다.
논문에서도 Discussion으로 마무리합니다.
결론은 다음과 같습니다.
"에이전트는 제안한 SA-learning과 SA-learning을 통해 나온 SR을 이용하여 강화학습하는 것을 동시에 학습하면서 delayed reward 환경에서 TD-learning을 잘 해낼 수 있다."
그러나 여기서는 SA-larning의 몇 가지 한계를 제시하고 있습니다.
- 희소 보상 (sparse reward) 환경이 아닐 경우 SA-learning의 적용이 어려울 것으로 예상된다.
- 한 에피소드 내에서 delayed reward가 실제로 주어지는 상태의 등장 횟수에 민감하지 않다.
- g를 곱함으로써 c의 의미에 대한 수렴이 보장되지 않는다.
- Additive regression 모델을 사용하기 때문에 최적 credit assignment가 보장되지 않는다. 특히 복수의 상태가 같은 보상을 예측할 경우 그렇다.
1번은 애초에 sparse reward 환경을 풀려고 제안된 방법이기 때문에 당연해 보입니다.
2번에 대한 증명은 Supplementary 6.1에서 수학적으로 제시됩니다.
3번은 Supplementary 6.1에서 g와 c의 큰 자유도 때문에 야기된다고 이야기합니다.
4번에 대한 증명은 Supplementary 6.4에서 수학적으로 제시됩니다.
3, 4번에 대한 해결은 향후 연구의 방향이라고 합니다.
그러나 흥미로운 것은, Supplementary 6.3에서 제시된 내용입니다.
연구진들은 SA-learning을 통해 TD-learning 없이 직접 정책을 학습하는 것이 가능할 것으로 전망하고 있습니다.
현재 SA-learning에서는 action이 고려되고 있지 않은데, 향후 action을 함께 고려한 SA-learning을 설계할 예정으로 보입니다.
이 대목에서 혹시 딥마인드가 얼마안가 가치함수를 부정하는 논문을 내는 건 아닌지 조심스럽게 예측해봅니다.
핵심 리뷰 끝!





댓글 영역